Để Hermes chạy được chỉ cần một lệnh duy nhất.
Trên Windows, bạn chạy lệnh sau trong PowerShell:
Trên Linux, macOS, hoặc WSL, lệnh tương đương là:
Sau khi cài xong, hãy khởi động lại terminal rồi chạy hermes setup để mở luồng cấu hình có hướng dẫn (guided configuration flow), lần lượt chọn model, terminal backend, messaging gateway và thiết lập tool.
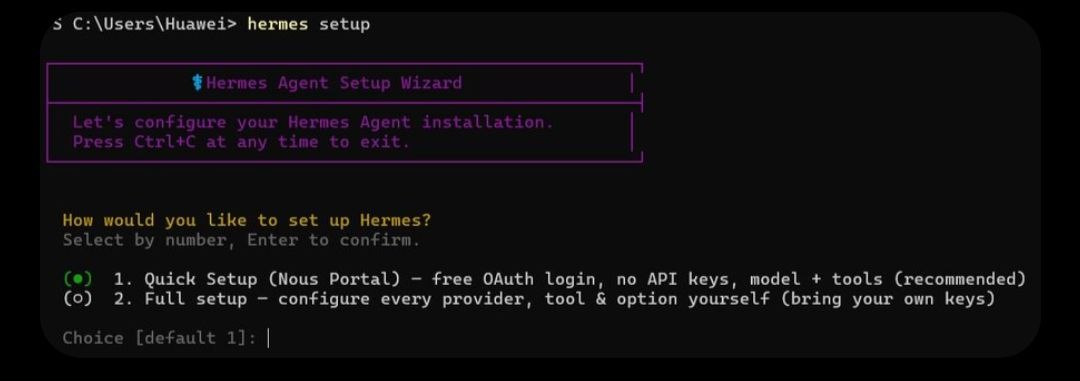
git (không phải script một dòng) để tiện hermes update theo nhánh — đang ở v0.16.0.Quyết định thực sự đầu tiên trong setup là chọn nhà cung cấp LLM nào sẽ vận hành "bộ não" của agent. Việc xác thực diễn ra qua OAuth thay vì raw API key, và điều này mở rộng tới khả năng đăng nhập bằng một phiên Claude Code hoặc Codex CLI sẵn có, thay vì phải tạo một API key riêng.
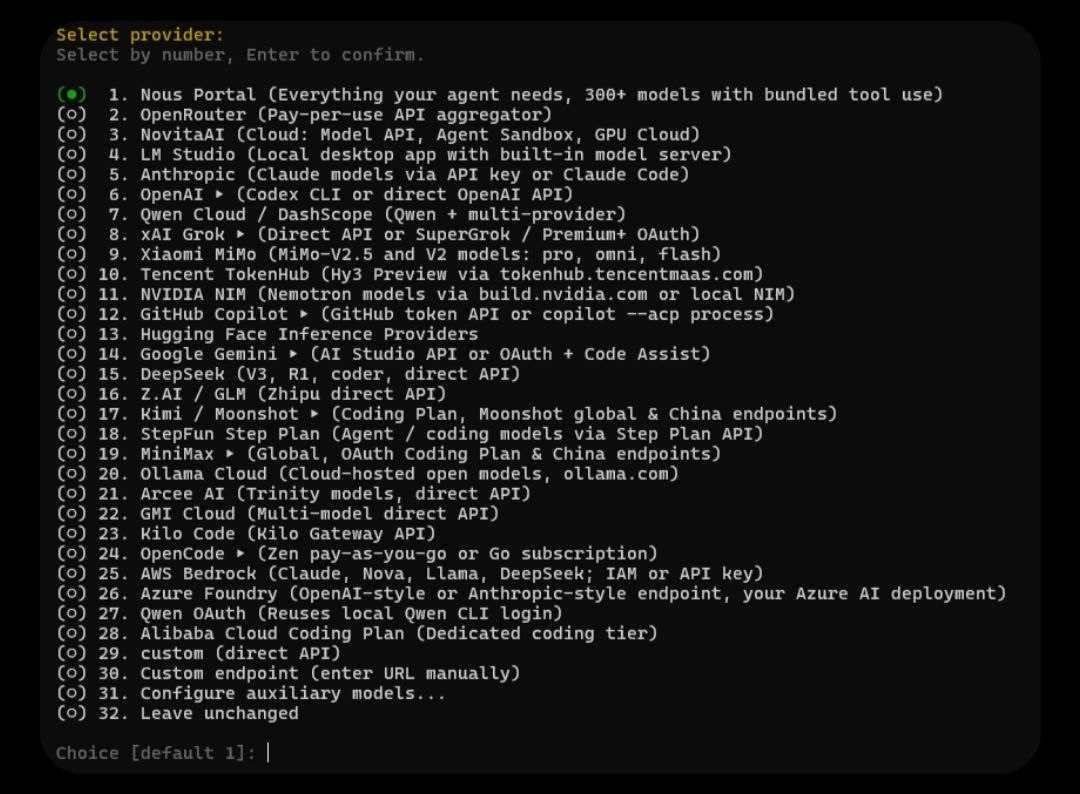
Điều thực sự được thiết kế tốt ở đây là cách Hermes tách model dùng cho cuộc trò chuyện chính khỏi các model dùng cho tác vụ nền (background) và phụ trợ (auxiliary). Theo mặc định, cùng một model lo cả hai, nhưng mỗi tác vụ phụ trợ có thể được trỏ tới một provider khác nhau một cách độc lập. Các tác vụ hỗ trợ kiểu override này là:
vision — phân tích và mô tả hình ảnhweb_extract — tóm tắt các trang web dàicompression — nén context của cuộc trò chuyện sắp vượt giới hạn (overflowing)title_generation — sinh tiêu đề cho sessioncurator — agent nền chịu trách nhiệm cho self-improving loopkanban_decomposer — chia nhỏ các tác vụ lớn thành subtask trong chế độ Kanbangoal_judge — agent kiểm tra xem một /goal đã thực sự đạt được hay chưaViệc này được cấu hình trực tiếp trong config.yaml, ví dụ:
Kiểu routing tường minh này giải quyết một vấn đề thực sự khi chọn OpenRouter làm lựa chọn mặc định: cùng một model trên danh nghĩa thường được triển khai bởi nhiều provider khác nhau, thường ở các mức quantization khác nhau, và OpenRouter sẽ âm thầm phân phối mỗi request mới cho một trong khoảng hai mươi provider đó.
Hệ quả thực tế là trong cùng một session, bạn không nói chuyện với một model nhất quán — bạn đang nói chuyện với một nhóm phiên bản được cấu hình khác nhau của cùng model đó, thay nhau xử lý request, trong đó một số xử lý tool call và prompt template đáng tin cậy hơn số khác. Định tuyến thủ công bên trong Hermes loại bỏ hoàn toàn điều này.
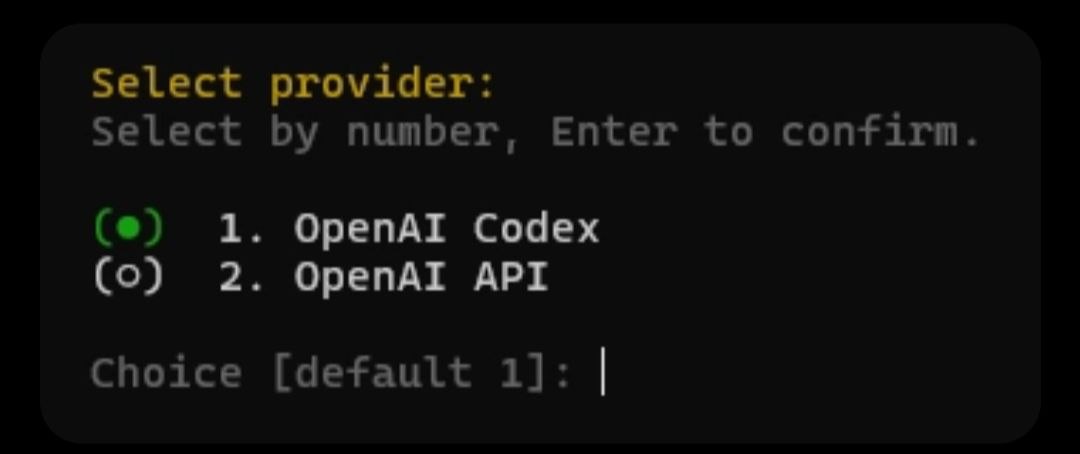
Cũng đáng lưu ý: nếu bạn muốn tiết kiệm tiền cho model hội thoại mà không hy sinh chất lượng code, Hermes hỗ trợ các lệnh /claude_code và /codex để ủy thác (delegate) các tác vụ coding trực tiếp cho những CLI tool đó thay vì để model chat đã cấu hình tự xử lý.
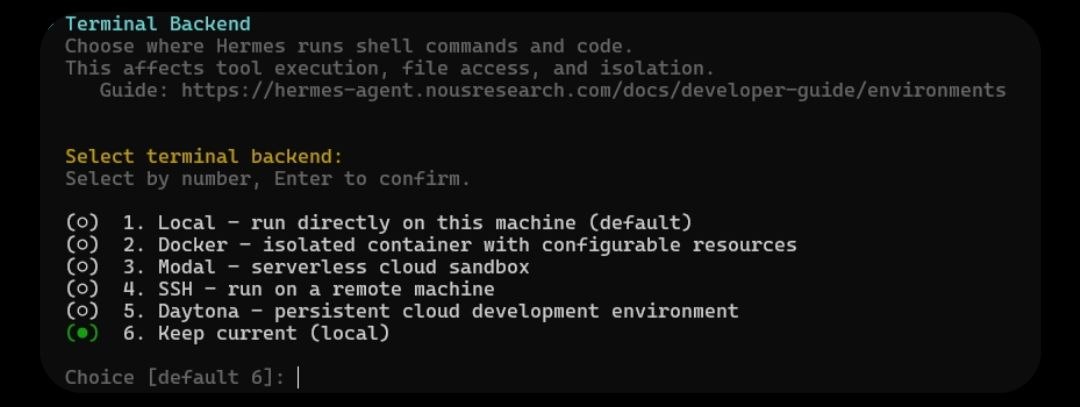
Một mảnh cốt lõi của kiến trúc là Terminal Backend Environment, thứ quyết định các lệnh shell và script Python được thực thi ở đâu, theo cách nào, và cách agent chạm vào filesystem của bạn. Hermes hỗ trợ năm loại.
Local là mặc định. Lệnh chạy trực tiếp trên máy của bạn với cùng quyền hạn như tài khoản người dùng của bạn — không có cách ly (no isolation). Đây là lựa chọn đúng cho phát triển cục bộ và việc dùng cá nhân tin cậy, khi bạn muốn agent chỉnh sửa trực tiếp các file dự án thật của mình.
Sự an toàn ở đây hoàn toàn dựa vào một hệ thống approvals (phê duyệt) tích hợp sẵn, vốn chặn các lệnh phá huỷ (một rm -rf /, một DROP TABLE) và hỏi xin phép tường minh trước khi chạy.
Docker chạy agent bên trong một sandbox cách ly để nó không thể chạm vào host system của bạn.
SSH cho phép agent thực thi lệnh và làm việc với file trên máy chủ từ xa qua kết nối remote.
Modal chạy mọi thứ trong các serverless cloud sandbox — về cơ bản bạn thuê compute theo từng giây, chỉ trả tiền cho đúng số giây code của bạn thực sự chạy.
Daytona là một lớp quản lý container (container-management layer) được xây dựng riêng cho các AI coding agent; nó nhanh hơn so với chạy Docker trực tiếp và tự động lo việc thiết lập môi trường cũng như cài đặt dependency.
Sau terminal backend, setup chuyển sang chọn nơi bạn sẽ thực sự nói chuyện với agent — Telegram là lựa chọn hoàn thiện nhất. Chọn Telegram sẽ cho bạn một đường link để tạo trực tiếp bot đã được cấu hình sẵn; không có bước thiết lập bot-token thủ công nào cả.
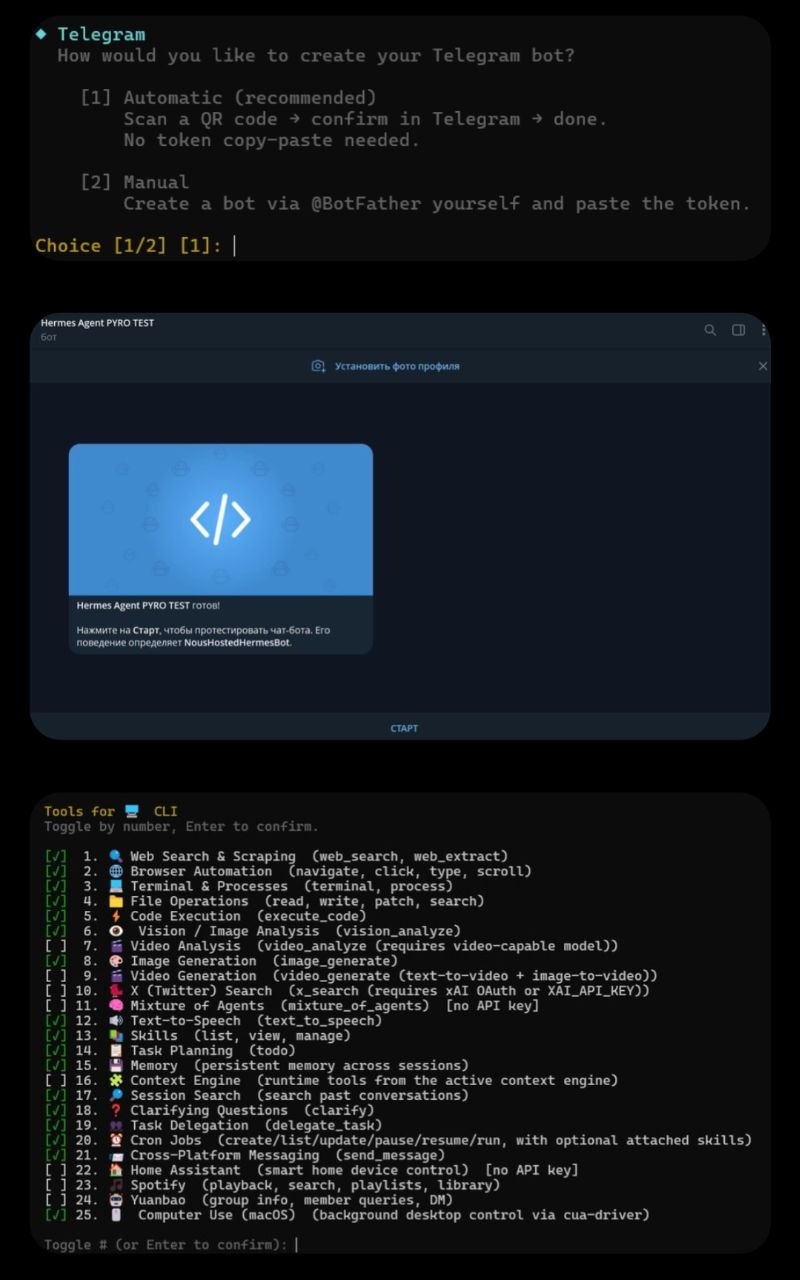
Phần còn lại của setup đi qua việc bật từng tool riêng lẻ và các provider tương ứng của chúng — browser automation, image generation, text-to-speech, và web search. Riêng với web search, Firecrawl tự host hoặc Exa nổi bật như những lựa chọn mạnh cho việc scraping và truy hồi (retrieval) dành cho agent.
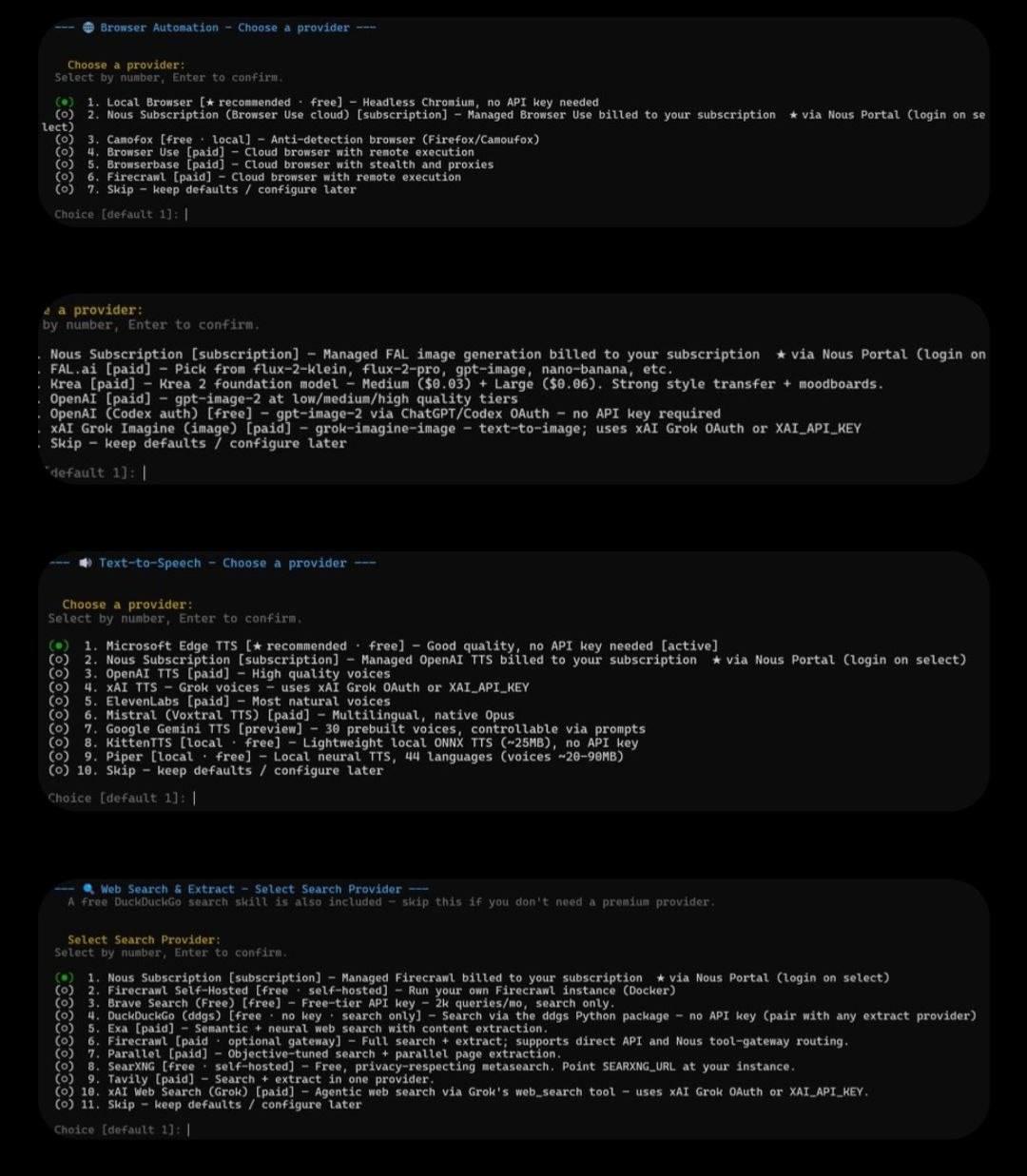
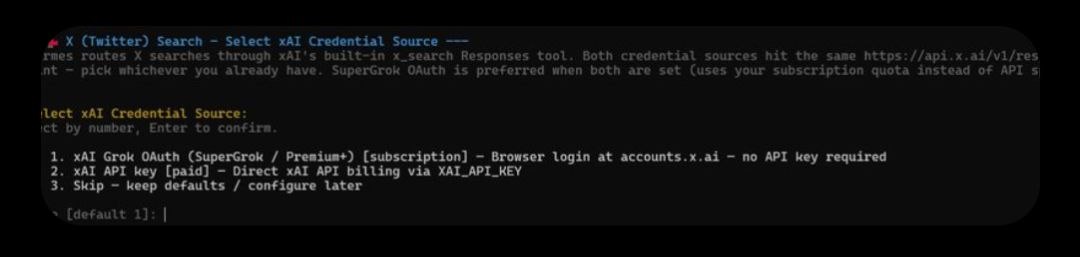
X search yêu cầu một thuê bao Grok (Grok subscription) mới bật được — điều đáng biết trước khi bạn đi tìm nó trong menu.
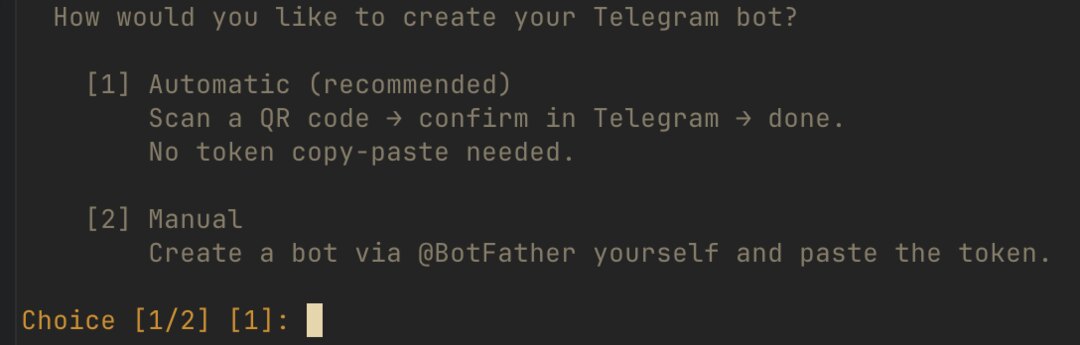
Khi đến phần Telegram trong hermes setup, đây là toàn bộ quy trình thiết lập thủ công (Manual) — bạn tự tạo bot và tự giữ token, toàn quyền kiểm soát.
Ở câu hỏi «How would you like to create your Telegram bot?», gõ 2 rồi Enter để chọn Manual — Create a bot via @BotFather yourself and paste the token. (Tuỳ chọn [1] Automatic dùng QR code cũng được, nhưng Manual cho phép bạn giữ token để tái sử dụng.)
Setup sẽ hỏi bot token. Để có token, mở Telegram và làm việc với @BotFather — tài khoản chính thức để tạo bot:
/newbot.TheAnh Buddy.bot, ví dụ TheAnhBuddyBot.123456789:AAE… → copy và dán vào Hermes setup khi được hỏi token.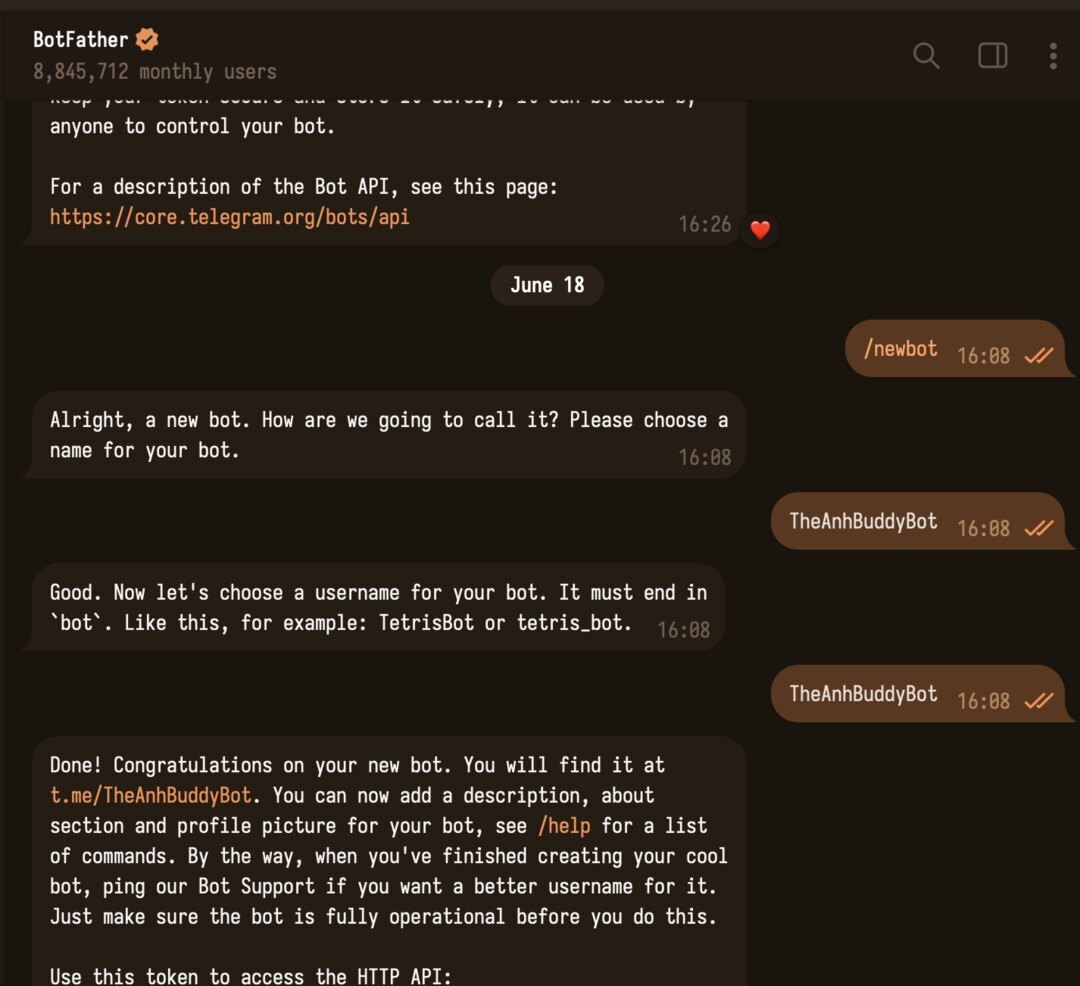
/newbot → tên → username → token để dán vào setup.Tiếp theo setup hỏi user id (để giới hạn ai được phép nói chuyện với agent) — hãy điền Telegram user id của chính bạn. Lấy id bằng cách:
/start — bot trả về dòng Id: 123456789 (đó là user id của bạn).Id đó vào Hermes setup.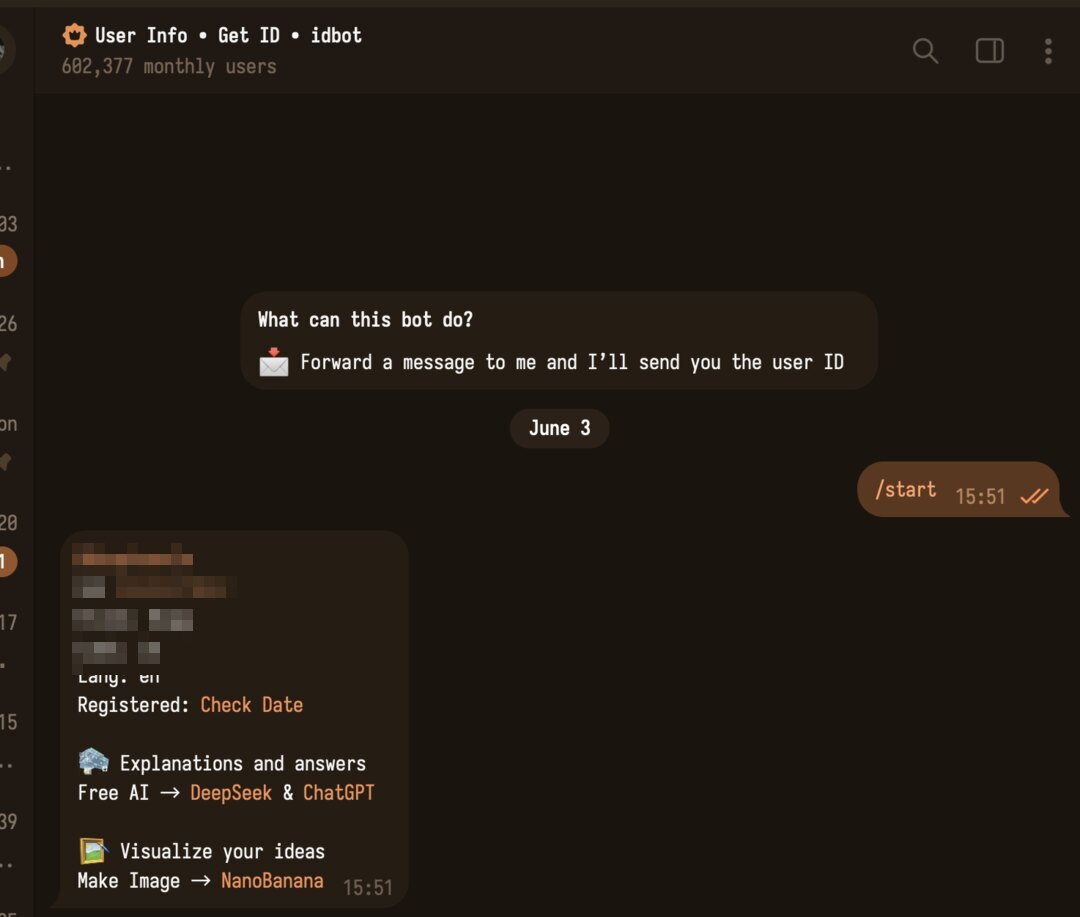
Id — chính là Telegram user id cần điền.Context engine chi phối cách Hermes nén và quản lý lịch sử trò chuyện một khi nó tiến gần đến giới hạn token (token limit) của model, và có hai lựa chọn.
Lựa chọn mặc định, Compressor, áp dụng phương pháp tóm tắt có mất mát (lossy summarization) cho phần giữa của cuộc trò chuyện dài.
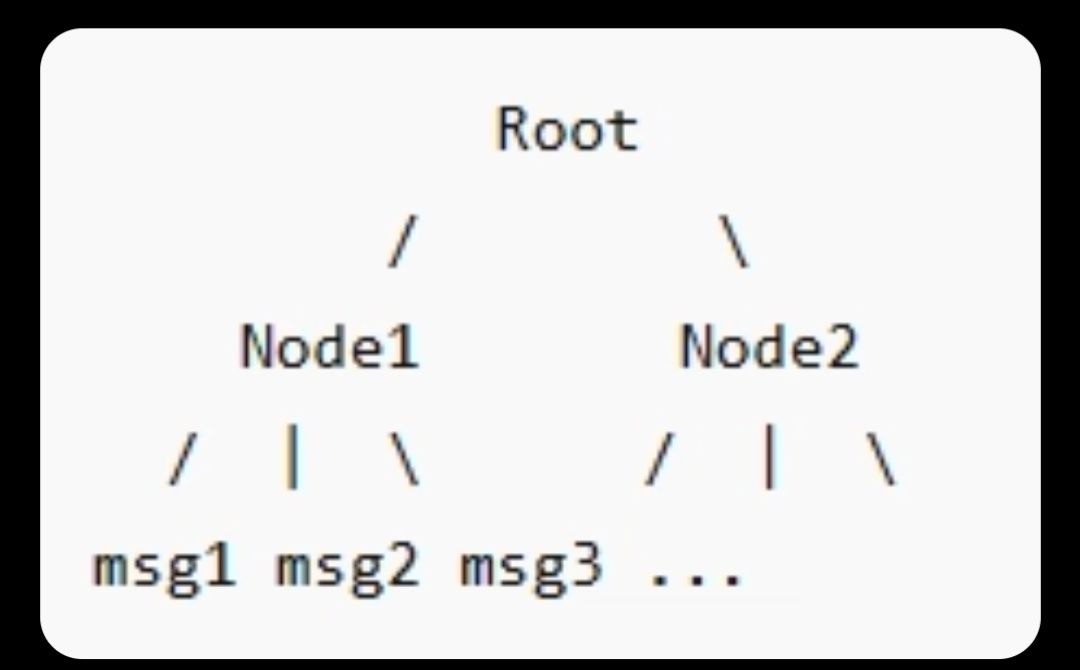
Lựa chọn thay thế, LCM (Lossless Context Management), áp dụng một cách tiếp cận khác về cấu trúc: thay vì sinh ra một bản tóm tắt dạng văn bản, nó dựng nên một đồ thị có hướng không chu trình (directed acyclic graph — DAG) của các điểm chính trong cuộc trò chuyện, cho phép agent điều hướng từ một góc nhìn tổng quan, được nén mạnh, xuống tới chính những thông điệp gốc cụ thể làm cơ sở cho nó.